.png)
Navigating the AI Revolution: How Strong Data Governance Can Make or Break Your Organization
- Tejasvi A
- Oct 12, 2024
- 7 min read

Updated: Oct 17, 2024
What is Data Governance and why is it important in the age of AI & LLM?
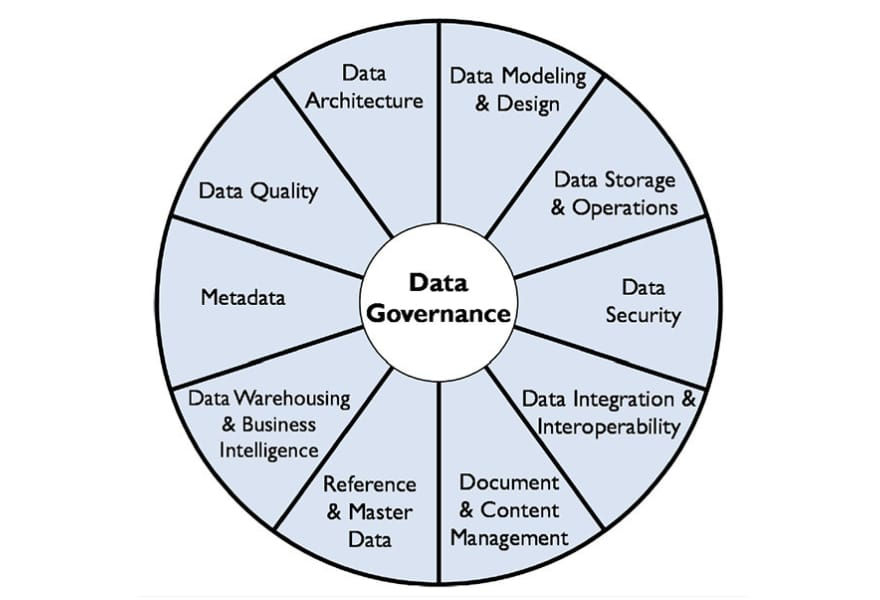
Data governance is the formalization of processes and policies designed to manage data assets within an organization. It involves allocating roles, decision-making rights, and accountability for information-related processes. In simple terms, it's about creating a structured framework to ensure data is used correctly, consistently, and securely. Its importance lies in the increasing volume and complexity of data in the digital age.
Formalizing data governance processes can help organizations maximize the value of their data and ensure it is used responsibly while using Artificial Intelligence and Large Language Models.
Data Quality: AI systems, including LLMs, are only as good as the data they are trained on. Poor data quality leads to poor AI performance.
Security and Privacy: With AI systems handling vast amounts of data, ensuring that data is protected from breaches and misuse is crucial.
Ethical Use: Proper governance helps in maintaining ethical standards, ensuring data is used responsibly and bias is minimized.
Compliance: Adhering to legal and regulatory requirements is a must. Data governance helps organizations stay compliant with laws like GDPR or the CCPA.
Transparency and Trust: Good governance builds trust with users, showing that their data is handled responsibly.
How has the concept of Data Governance evolved?
Data governance is a relatively new concept that gained prominence in the 1980s, evolving from the earlier concept of IT governance, itself rooted in corporate governance. Initial frameworks focused on roles and responsibilities but lacked maturity in implementation and monitoring. Over time, data governance frameworks have become more sophisticated.
Standardization: Popular frameworks define key decision domains like data quality, metadata, and data access.
Scalability: Some further frameworks introduced core mechanisms (structural, procedural, and relational) to enhance the scalability of data management.
Industry-Specific Adaptations: Alignment with IT and risk management frameworks, such as NIST principles.
Focus on Collaboration: Emphasizing the importance of negotiation and agreement between stakeholders regarding data usage.
Contingency and Social Factors: Recognizing the influence of external factors like firm size, industry, and cultural differences on data governance models.
What is the Contingency Model for Data Governance?
The contingency model acknowledges that there is no one-size-fits-all approach to data governance. It suggests that the "optimal" data governance structure is contingent on various factors:
Internal Factors: Firm size, organizational structure, competitive strategy, corporate governance culture, and decision-making style.
External Factors: National and cultural differences, industry regulations, and market dynamics.
The model emphasizes the need to consider these factors when designing a data governance operating model to ensure its effectiveness and alignment with organizational goals.
For more details on creating a contingency model for your organization, please refer to the article linked below. Click on the article to learn more.

What is the Evolutionary Model for Data Governance?
The Evolutionary Model views data governance as a dynamic process that adapts and improves over time, similar to Darwinian evolution. It highlights the importance of continuous learning, adaptation, and innovation in data management.
Key aspects of this model include:
Variation, Selection, Retention: Data governance models should allow for experimentation and adaptation, selecting and retaining successful approaches.
Learning Loops: Encouraging feedback, evaluation, and adjustments at the individual, group, and organizational levels.
Data as a Service (DaaS): Formalizing data management as a service with sub-units like Data Quality Management (DQM) to improve efficiency and responsiveness.
Target Operating Model (TOM): Define modular functional units that encapsulate skills, routines, and technology for effective collaboration in data management.
For more details on creating a evolutionary model for your organization, please refer to the article linked below. Click on the article to learn more.
How does Data Governance relate to Corporate Governance and Financial Performance?
Data governance is intrinsically linked to corporate governance. While corporate governance focuses on overall organizational direction and accountability, data governance ensures responsible and ethical management of data assets, which directly impacts a company's financial performance.
Here's how:
Transparency and Accountability: Good data governance aligns with corporate governance principles by promoting transparency, accountability, and responsibility in data handling.
Risk Management: Effective data governance mitigates risks associated with data breaches, regulatory non-compliance, and reputational damage, protecting shareholder value.
Data-Driven Decision Making: High-quality data, enabled by good governance, leads to more informed decisions, improving operational efficiency and profitability.
Investor Confidence: Robust data governance practices inspire confidence in investors, potentially leading to higher valuations and better access to capital.
What is the role of a Chief Data Officer (CDO) in data governance?
The Chief Data Officer (CDO) is a senior executive responsible for overseeing data strategy and governance within an organization. They play a crucial role in:
Developing and Implementing a Data Strategy: Aligning data governance practices with overall business goals.
Establishing a Data Governance Framework: Define policies, procedures, and standards for data management.
Ensuring Data Quality and Security: Implementing measures to guarantee the accuracy, consistency, and protection of data assets.
Promoting Data Literacy: Fostering a data-driven culture within the organization.
Monitoring and Reporting: Tracking data governance metrics and reporting on progress to the board and stakeholders.
The presence of a CDO, especially one with long tenure and C-level authority, has been linked to positive firm performance, demonstrating the importance of strong leadership in data governance.
What are the challenges in implementing effective data governance?
While the benefits of data governance are clear, organizations often encounter challenges.
Lack of Awareness and Understanding: Limited understanding of data governance principles and their importance can hinder implementation.
Resistance to Change: Shifting to a data-driven culture requires overcoming resistance from individuals and departments accustomed to existing practices.
Data Silos: Overcoming data silos within an organization to ensure data is shared and used effectively can be challenging.
Finding the Right Talent: Attracting and retaining skilled data professionals, including data stewards and data scientists, can be a major hurdle.
Keeping Pace with Technology: The rapid evolution of technology necessitates continuous adaptation and updates to data governance frameworks.
What are some key considerations for the future of Data Governance?
As data continues to proliferate, the future of data governance will be shaped by:
Increased Regulation: Evolving data privacy regulations like GDPR and CCPA will require ongoing adjustments to ensure compliance.
Artificial Intelligence (AI) and Machine Learning: The rise of AI necessitates new governance mechanisms to address ethical considerations and potential bias.
Data Ethics: Growing emphasis on responsible data use and the ethical implications of data-driven decisions.
Data Democratization: Enabling wider access to data within organizations while maintaining appropriate security and control measures.
Cross-Organizational Data Sharing: Establishing frameworks and standards for secure and ethical data sharing between organizations.
Successfully navigating these challenges and embracing the evolving landscape of data governance will be crucial for organizations aiming to thrive in the data-driven future.
Why does quality of data matter in insights generated from LLMs?
The quality of data plays a pivotal role in both prompt engineering and fine-tuning of Large Language Models (LLMs) for a specific domain or organization. Here’s how it impacts these processes:
Impact on Prompt Engineering:
Prompt engineering involves crafting specific inputs (prompts) to elicit the desired response from an LLM. The quality of data directly influences how well the model responds to prompts in a given context or domain. Poor-quality data can introduce several challenges:
Ambiguity in Responses: If the data used to guide the prompt creation is inconsistent, contradictory, or lacks context, it can lead to unclear or ambiguous responses from the LLM. In contrast, high-quality, domain-specific data helps in crafting prompts that are precise and lead to more relevant, accurate outputs.
Contextual Relevance: When dealing with tasks specific to certain domains such as legal, medical, or financial industries, if the data used to guide prompt creation does not accurately reflect that domain, the model might face difficulties in producing outputs that match the industry's terminology or nuanced comprehension. High-quality data guarantees that the prompts are customized to the particular knowledge and context of the organization, thereby boosting the model's effectiveness in specialized fields.
Increased Reliability: With high-quality data, prompt engineering can focus on the critical variables and factors that influence decision-making in a specific domain. This makes the LLM more reliable, as it is guided by the correct context, reducing the chances of generating off-topic or irrelevant answers.
Bias Mitigation: Poor-quality data can introduce biases, which can manifest in undesirable outputs. If data used in prompt engineering contains biased information, the resulting model responses can be skewed or unfair. High-quality data helps in minimizing biases, allowing for more equitable and accurate results.
Impact on Fine-Tuning:
Fine-tuning an LLM on a specific dataset allows it to adapt and specialize in a particular domain or task, improving its performance in that context. Here’s how data quality affects the fine-tuning process:
Accuracy and Relevance: Fine-tuning is heavily reliant on the quality of the training data. If the data is inconsistent, noisy, or poorly labeled, it hampers the model’s ability to learn accurate representations of the domain-specific language, leading to subpar performance. High-quality, well-curated data ensures that the model fine-tunes on relevant and domain-specific information, resulting in more accurate and context-aware outputs.
Data Labeling and Annotation: For supervised fine-tuning, proper labeling is essential. If the data is mislabeled, the model will learn incorrect associations, which degrades the model’s performance. Quality data includes clear, well-annotated examples that accurately reflect the expected output for each input, which helps the LLM learn in a meaningful way.
Avoiding Overfitting: Overfitting occurs when a model becomes too specialized to the training data and loses generalizability. Poor-quality data with noise or irrelevant examples can exacerbate this issue, causing the model to overfit to bad patterns. High-quality, clean data minimizes noise and ensures that the model fine-tunes in a way that enhances performance while maintaining generalizability.
Generalization to Real-World Data: Quality data for fine-tuning should reflect the real-world data distribution the model will encounter in practice. If the training data is too narrow or not representative, the model may struggle to generalize its learned knowledge to unseen inputs. A diverse, high-quality dataset helps the model generalize better to a wide range of inputs within the domain.
Efficiency of Training: High-quality, well-structured data can also reduce the amount of data required to achieve effective fine-tuning. In some cases, fine-tuning on clean, high-quality data can lead to better performance with fewer iterations and data points, saving computational resources and time.
Summary: Why Quality Data Matters in AI & LLMs
Improves Model Accuracy: High-quality, domain-specific data helps the LLM generate more accurate, relevant, and context-aware outputs by aligning with the specific needs and language of the organization.
Reduces Bias: Clean data minimizes the risk of introducing biases in both prompt responses and fine-tuned outputs, leading to fairer, more reliable AI applications.
Enhances Model Efficiency: Well-structured and relevant data allows for faster, more effective fine-tuning, improving model performance without excessive training time.
Ensures Real-World Relevance: Data quality ensures that the model can generalize well to real-world scenarios and avoid overfitting, which is essential for producing actionable insights in specific domains.
Ultimately, the quality of your data is the foundation upon which your AI applications—whether through prompt engineering or fine-tuning—are built. Without clean, well-curated, and domain-relevant data, the potential of LLMs to deliver accurate, high-quality outputs is limited.



Comments